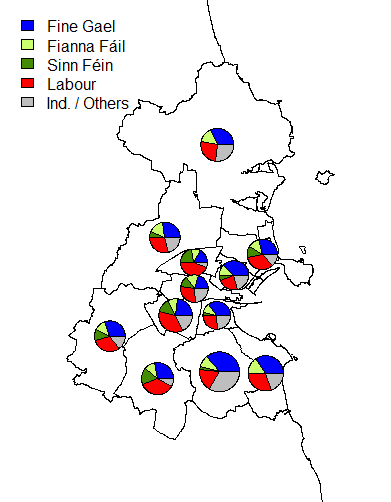
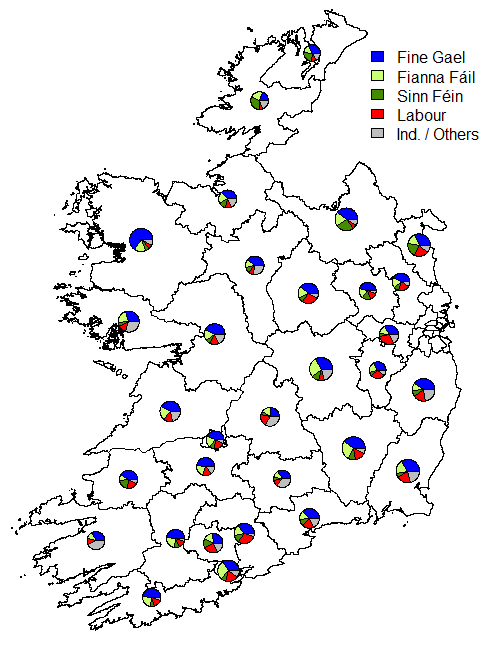
One of the unusual features of the Irish electoral system is that of transferable voting. Since the constituencies (other than in by-elections or in Presidential elections) have more than one seat to be filled, the bigger parties often run more than one candidate.
They often try to spread the candidates out geographically throughout the constituency, in order to try to capture geographic transfers as well as party transfers.
Using an example, from a 3-seat constituencies: Cork North West, I will explain how the transfer system works. The calculation for the quota (the point at which a candidate is elected) is as follows:

where NVotes is the number of valid votes, and NSeats is the number of seats being contested. Thus in the case of a three seat constituency, a candidate has to accumulate one vote more than 25% of the number of valid votes to be automatically elected [note that this doesn’t apply at the final count, as some votes are not transferred and so the effective number of votes is reduced].

Count 1: All number 1 preferences are counted for each candidate.
At the end of Count 1, in the case of Cork North West, no candidate was elected, so they decided to eliminate candidates. In this case the three candidates (O’Donnell, Griffin and O’Sullivan) with the fewest 1st preferences were eliminated together.
Why aren’t they eliminated one at a time? Well, consider the case of the four lowest polling candidates:
- Green Party: C. Manning 1354
- Independent: J. O’Sullivan 478
- Independent: S. Griffin grey 439
- Communist Party: M. O’Donnell 185
The sum of 2-4 on this list is 1102. So therefore, if they were to be eliminated one at a time, and all the transfers went to the next highest in the queue – so all O’Donnell’s 185 1st preference votes were transferred (by expressing number 2 preference) to Griffin (to result in a value of 624 votes for Griffin) and then O’Sullivan is eliminated (still having only 478 votes, having received no direct transfers from Griffin) and all O’Sullivan’s votes also go to Griffin, Griffin would still only have 1102 votes, which is less than Manning’s 1354.
Therefore, after Count 1, all of the ballot papers that had 1st preferences for O’Sullivan, Griffin or O’Donnell are then examined and the 2nd preferences are looked at. The votes are then literally transferred into the candidates’ that received the number 2 rank pile of ballot papers.
At the end of Count 2, still no one has reached the quota, so Manning (the remaining candidate with the fewest votes) is eliminated. Any of Manning’s votes that attempt to make their next preference for one of the already eliminated candidates have their next available preference considered. Note that, since a Supreme Court judgement, if a voter forgets to include a preference – so gives ranks 1-3, forgets 4, restarts at 5, then all preferences after 3 are deemed invalid and the vote becomes non-transferable.
This process continues until Count 8, when a candidate is elected (if more than one is elected on the same count, the one with the greater surplus is considered first; if the excess is so small as to not to make a difference to potential order of elimination/election, they may choose to go straight to the next elimination). Counters look at the last pile of votes added into Creed’s pile of votes – the transfers from Collins, another candidate from the same political party. They look at all the next preferences in this pile and then split the number of excess votes in proportion to the next available preference (after Creed). In this case, the majority of these went to O’Shea. The votes they choose to distributed the excess from are randomly sampled [so as they do not consider lower order preferences, this could, potentially effect who are elected] – but it did not matter in this case, as Count 9 was the last count.
In this count, A. Moynihan exceeded the quota and was deemed elected.
M. Moynihan was then elected without them checking A. Moynihan’s excess as M. Moynihan was sufficiently far in excess of the only other remaining candidate (O’Shea) that it would not have made a difference, even in the unlikely event that all of A. Moynihan’s votes went to O’Shea (although of the same party, the two Moynihans are not related). Thus M. Moynihan was elected without making the quota, because, by Count 9 there were 3,650 untransferred votes, making it impossible for the final person elected to exceed the quota.